1. 하둡이란

정의: 아파치 하둡(Apache Hadoop)은 대량의 자료를 처리할 수 있는 큰 컴퓨터 클러스터에서 동작하는 분산 응용 프로그램을 지원하는 프리웨어 자바 소프트웨어 프레임워크이며, 분산처리 시스템인 구글 파일 시스템을 대체할 수 있는 하둡 분산 파일 시스템(HDFS: Hadoop Distributed File System)과 맵리듀스를 구현한 것이다.
하둡의 핵심철학이 "코드(가벼움)를 데이터(무거움)가 있는 곳으로 보낸다" 인것에도 알 수 있듯이, 1대의 컴퓨터에 100개의 데이터를 처리하는 것이 아닌 100개의 각 컴퓨터에 1개의 데이터를 처리하는 병렬처리 개념으로 처리속도를 비약적으로 올린것이 하둡이다.
2. 하둡의 특징
- Distributed: 수십만대의 컴퓨터에 자료 분산 저장 및 처리
- Scalable: 용량이 증대되는 대로 컴퓨터 추가
- Fault-tolerant: 하나 이상의 컴퓨터가 고장나는 경우에도 시스템이 정상 동작
- Open source: 공개 소프트웨어
3. 하둡의 구조
분산 처리를 위한 Map&Reduce 모듈 (MR)과 MR에 Input/Output 데이타를 저장하는 파일시스템인
HDFS (Hadoop Distributed File System)로 구성
3-1.HDFS
하둡 네트워크에 연결된 기기에 데이터를 저장하는 분산형 파일 시스템
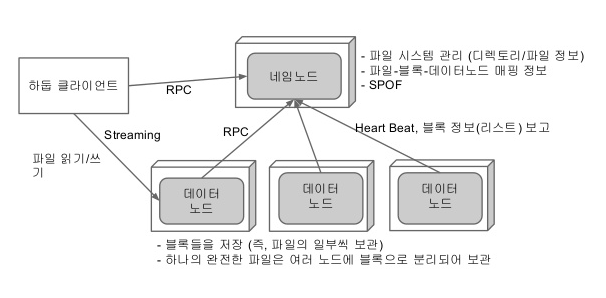
- 장애복구: 빠른시간안에 장애를 파악하고 대처할수 있도록 설계되었고, 복제 데이터가 존재하므로 데이터 손실을 방지
- 스트리밍 방식의 데이터 접근: HDFS는 스트리밍 방식으로 데이터에 접근하여 순차적으로 읽는방식이므로 대용량의 데이터를 순차적으로 처리하는데 적합
- 대용량 데이터 저장: GB, TB 이상의 크기도 파일도 저장가능
- 데이터 무결성: HDFS에 저장되 데이터는 read,append만 가능하며, 수정이 불가능
3-2.MapReduce
대용량의 데이터 처리를 위한 분산 프로그래밍 모델
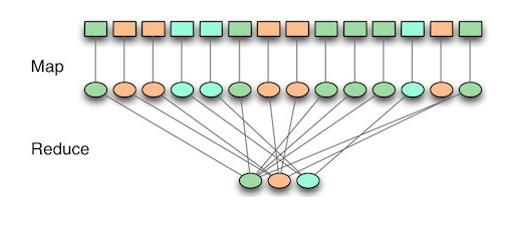
Map : 흩어져 있는 데이터를 연관성 있는 데이터들로 분류하는 작업. (key, value의 형태)
Reduce : Map에서 출력된 데이터에서 중복 데이터를 제거하고 원하는 데이터를 추출하는 작업
'빅데이터' 카테고리의 다른 글
| [Spark] Centos7에 Apache Spark 설치하기(+zeppelin) (0) | 2020.10.27 |
|---|---|
| [Hadoop] Centos7에 하둡 설치하기 (0) | 2020.10.27 |
| [Spark] 스파크가 뭘까?(+zeppelin) (0) | 2020.10.25 |
| GCP 에서 hadoop 설치 (0) | 2020.04.24 |